TimeLens: Rethinking Video Temporal Grounding with Multimodal LLMs
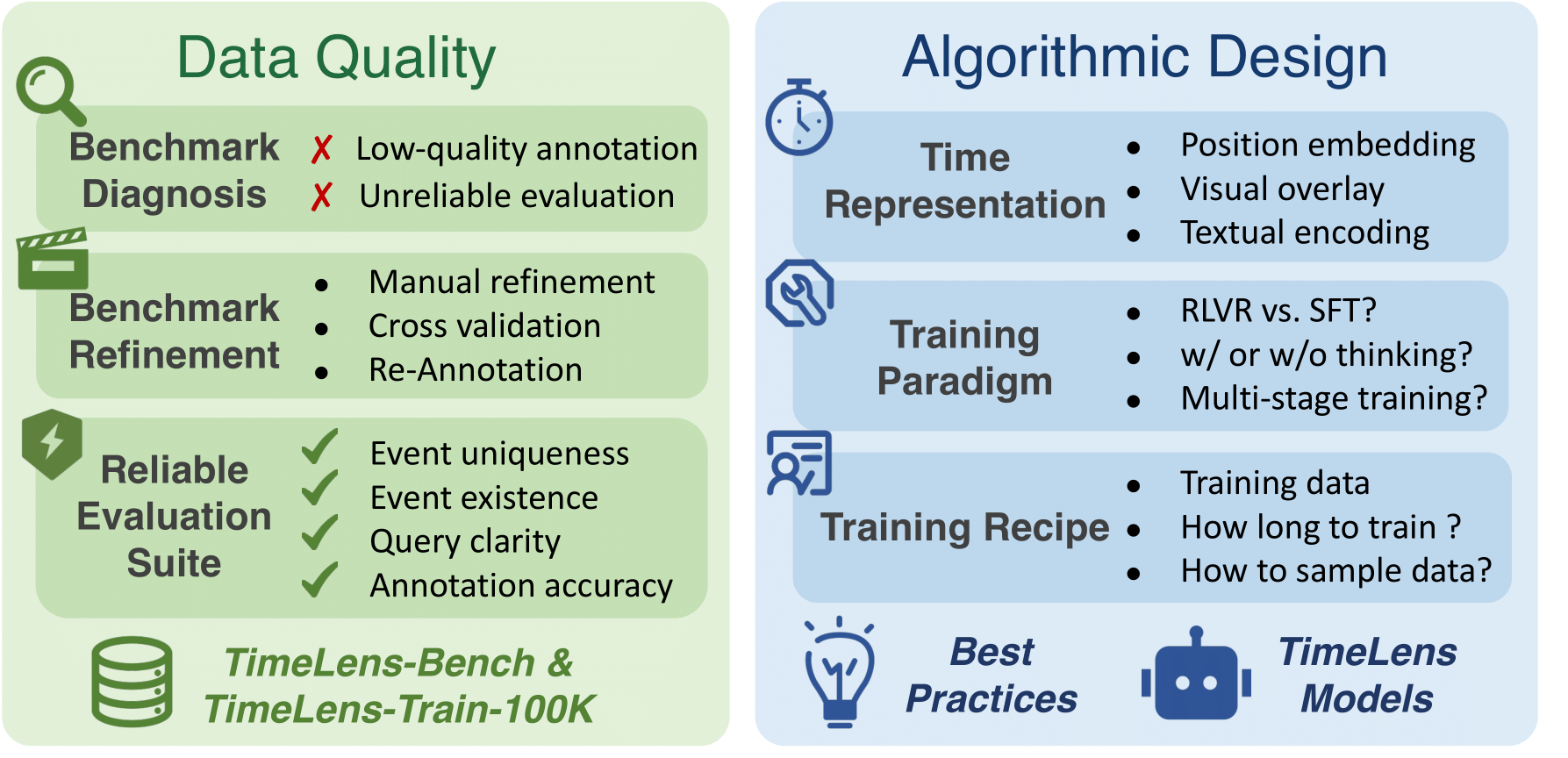
Rethinking Data Quality
Diagnosing Existing Datasets
We begin by establishing strict quality criteria for VTG annotation, ensuring query clarity, event existence, etc. Based on this, we introduce a rigorous Diagnose-then-Refine pipeline to manually audit and correct existing datasets.
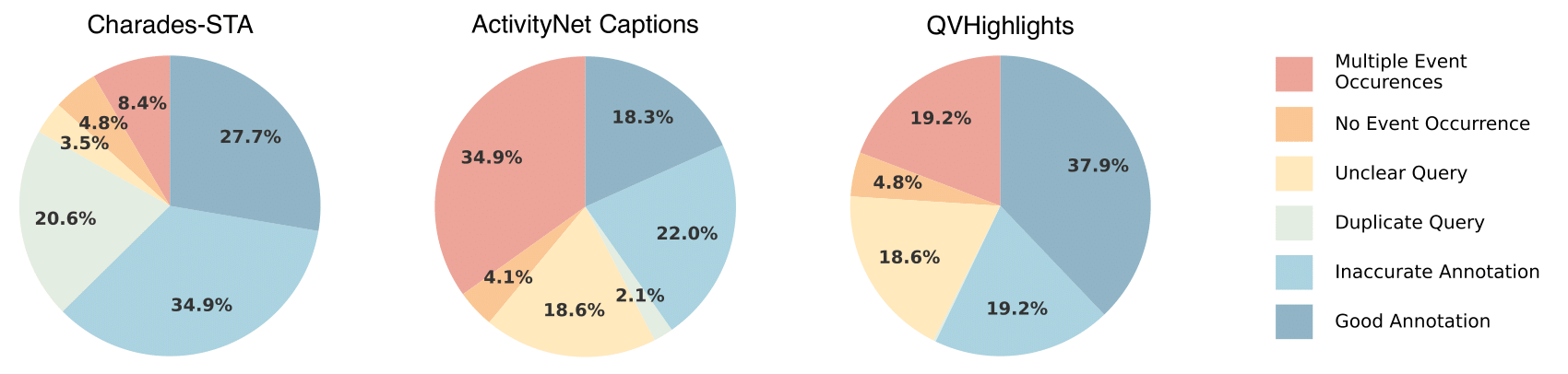
Applying this pipeline to three widely-used VTG benchmarks (Charades-STA, ActivityNet Captions and QVHighlights), we expose an alarmingly high proportion of errors.
While the error distribution varies by category, all datasets exhibit consistently high overall error rates.

TimeLens-Bench: Reliable Evaluation Suite
Through meticulous refinement and correction of the three aforementioned benchmarks, we present TimeLens-Bench, a comprehensive evaluation suite featuring both domain diversity and high-quality annotations.
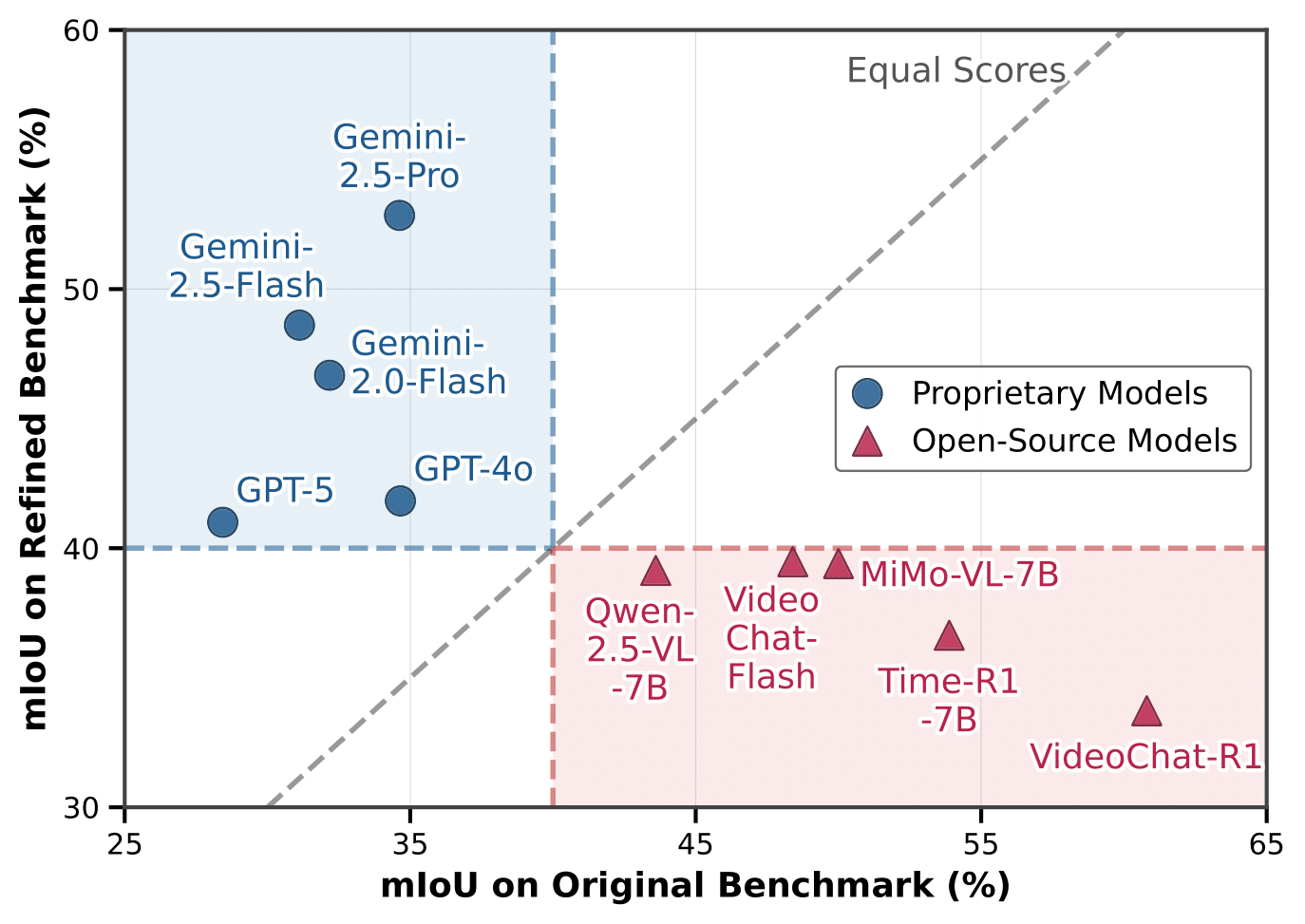
Benchmarking frontier models on both the original and refined benchmarks reveals drastically contrasting performance trends.
On original benchmarks, proprietary models receive poor scores, while performance of open-source model are deceptively inflated. Conversely, TimeLens-Bench exposes the true performance gap: proprietary models demonstrate better capabilities, while open-source models suffer substantial performance degradation.
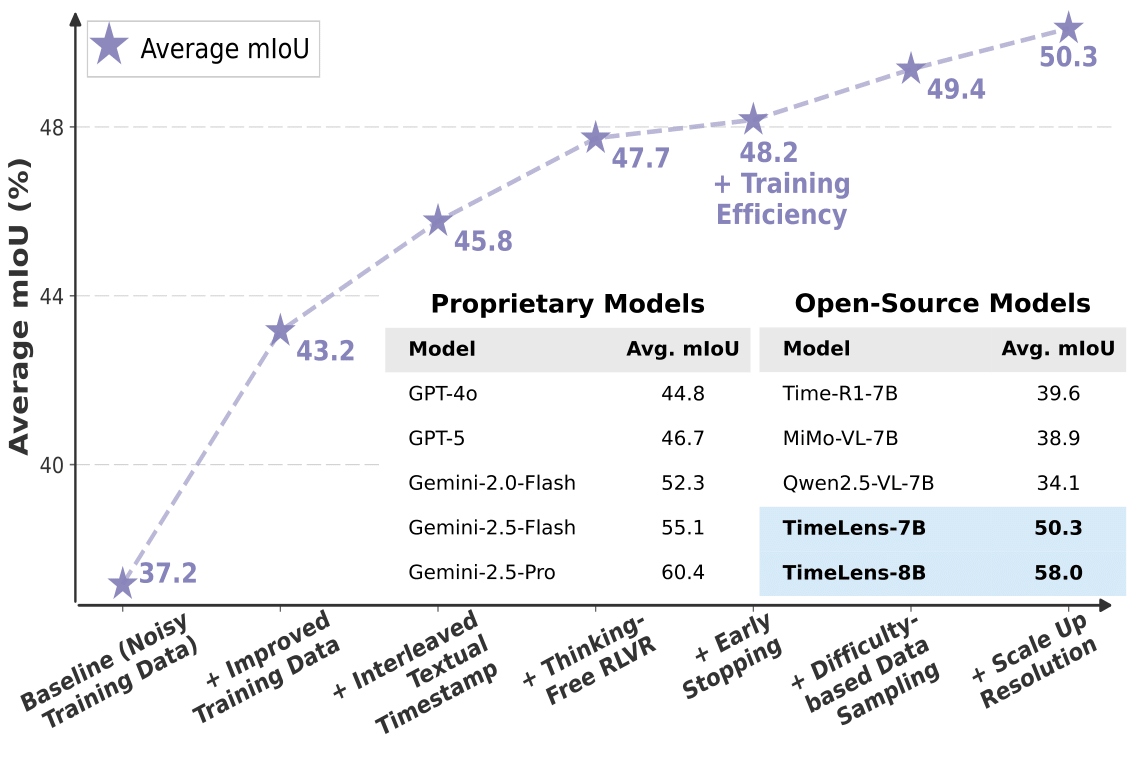
High-Quality Training Data
To address the even more severe noise in large-scale training corpora, we developed an automated re-annotation pipeline powered by Gemini-2.5-Pro. This process yielded TimeLens-100K, a large-scale, high-quality VTG training dataset. Compared to original noisy data, TimeLens-100K significantly improves model performance, validating its enhanced quality.

Exploring Algorithmic Designs
Timestamp Encoding
To enable MLLMs to perform temporal grounding, a critical design decision is timestamp encoding (i.e., aligning the timestamp of each frame with its corresponding features). We conduct a comprehensive comparison of different timestamp encoding methods:
- Position-embedding based methods adapt position embeddings in LLMs to represent the temporal position of each frame.
- Visual overlay methods directly overlay timestamps or frame index onto each frame.
- Textual encoding methods convert timestamps into text tokens using the MLLM's text tokenizer. There are two main variants: the interleaved approach inserts timestamp tokens before the visual tokens of each frame, while the non-interleaved approach adds an instruction specifying the timestamps of all frames into the prompt.
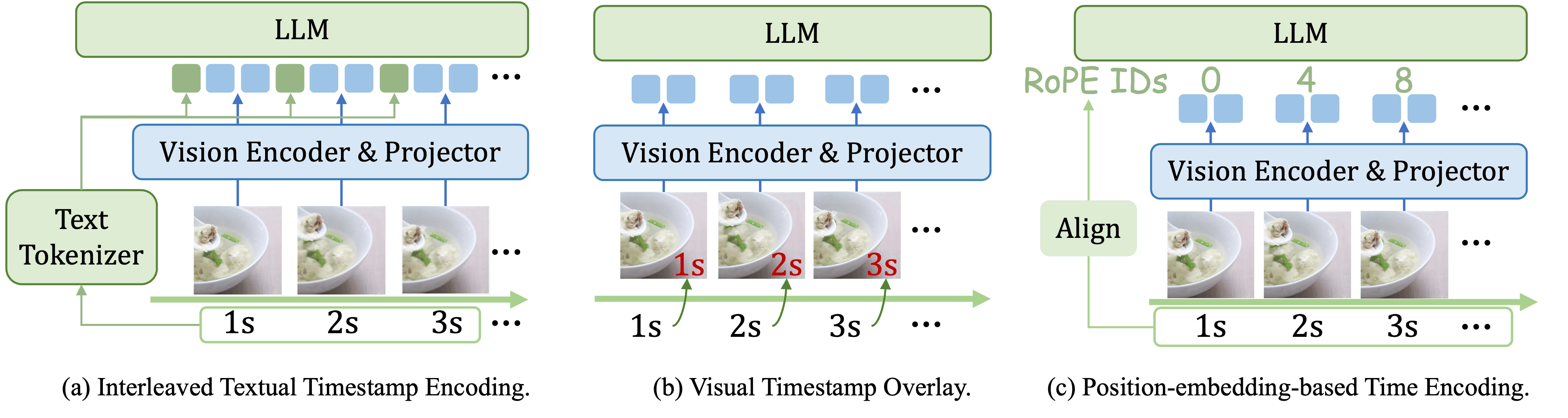
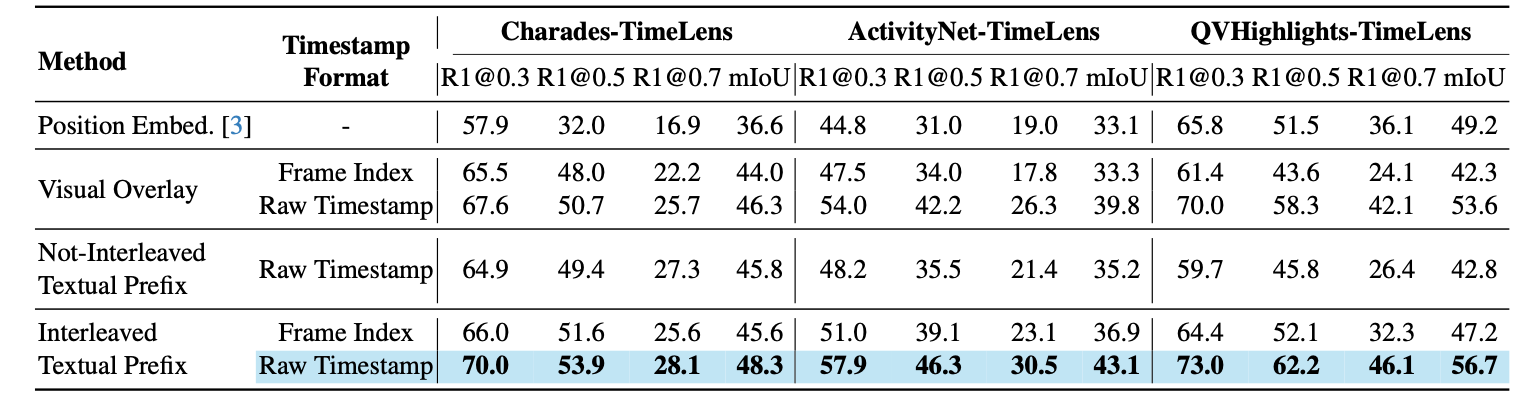
Our experiments reveal that interleaved textual prefix with raw timestamps achieves the best performance among all approaches, while remaining simple and intuitive.
Optimization Paradigms
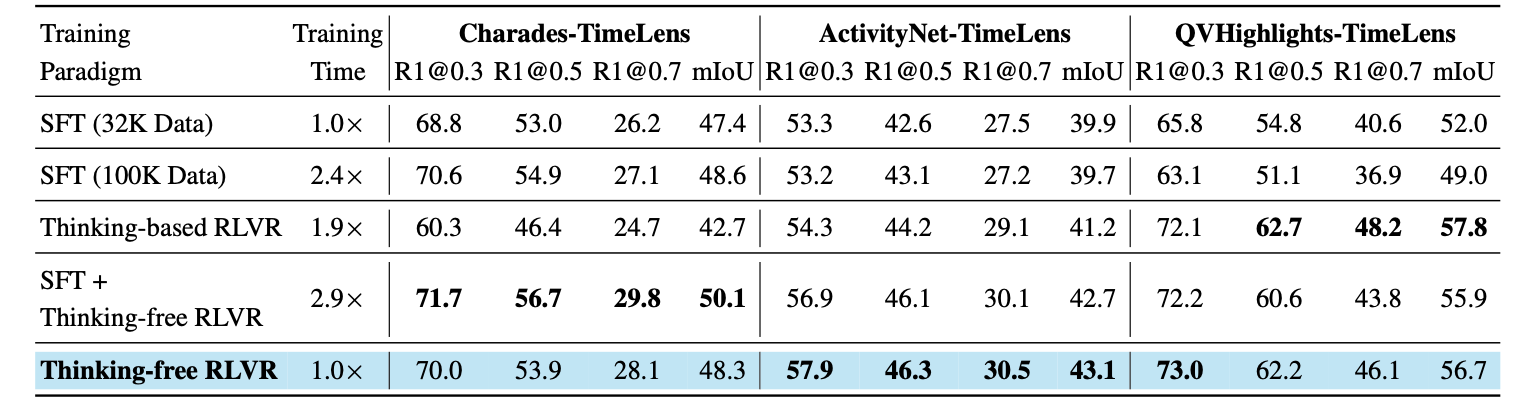
Supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR) are the two primary training paradigms for improving MLLMs' VTG capability. However, some key questions remain unanswered:
- Under equal training budgets (rather than equal amounts of training data), is RLVR superior to SFT?
- For VTG, which appears to be a predominantly perception-oriented rather than reasoning-oriented task, is the explicit thinking process in RLVR necessary?
- Does a preceding SFT phase facilitate subsequent RLVR training by raising the performance ceiling of the final model?
Our results reveal that a pure thinking-free RLVR approach maintains simplicity, superior performance, and high efficiency.
Adding a preceding SFT phase before RLVR yields no significant performance gain.
Effective RL Recipes
Building on the finding that thinking-free RLVR is the optimal training paradigm, we use the TimeLens-100K training corpus to further explore effective recipes for RLVR training, focusing on two key questions:
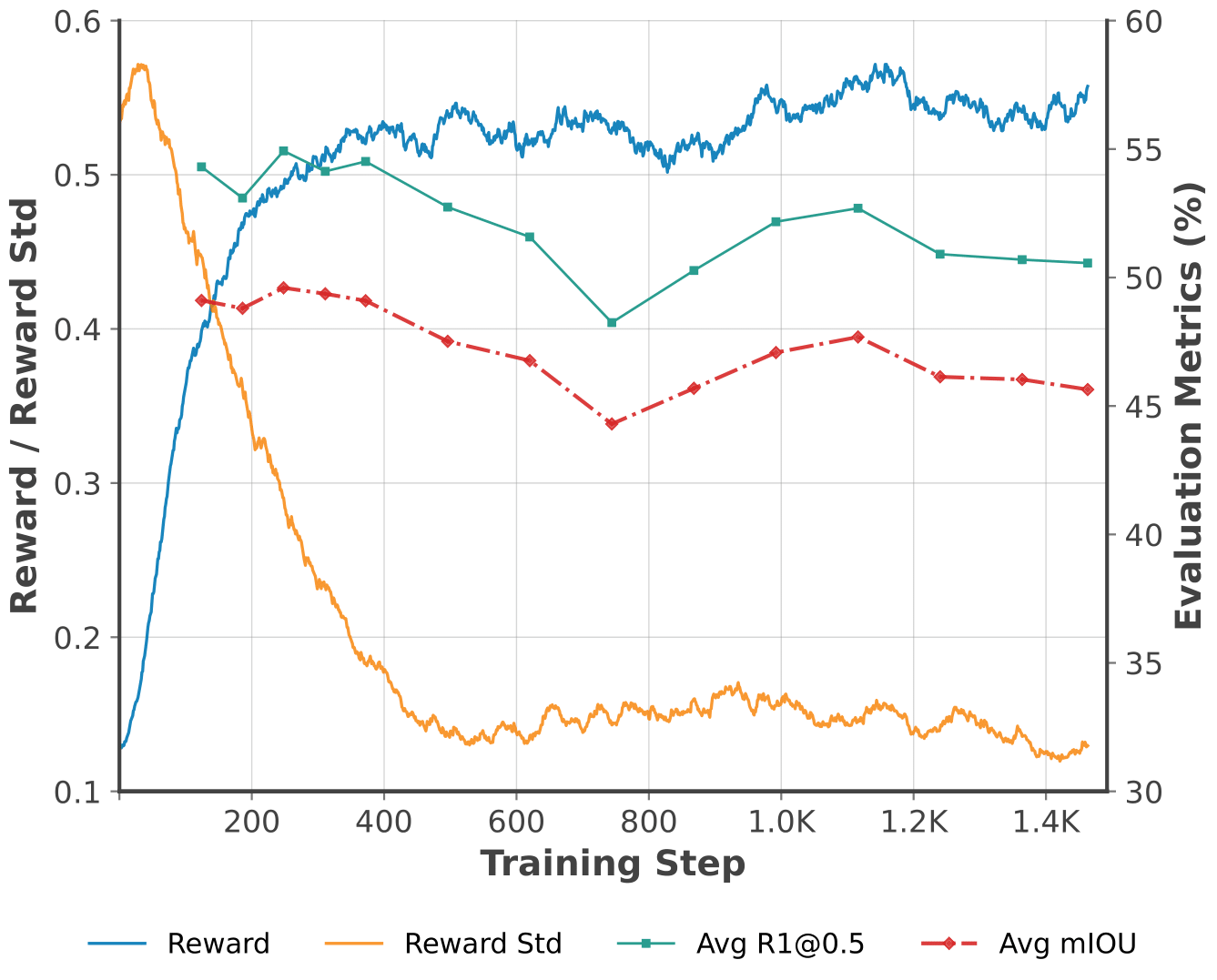
(i) How long should we train?
- We tracked reward metrics and evaluated model checkpoints at different training steps.
- When temporal IoU reward and within-group reward standard deviation plateau, model performance peaks.
- Continued training beyond this point causes performance degradation.
- Best practice: Perform early stopping when reward metrics plateau to save computation and prevent performance degradation.
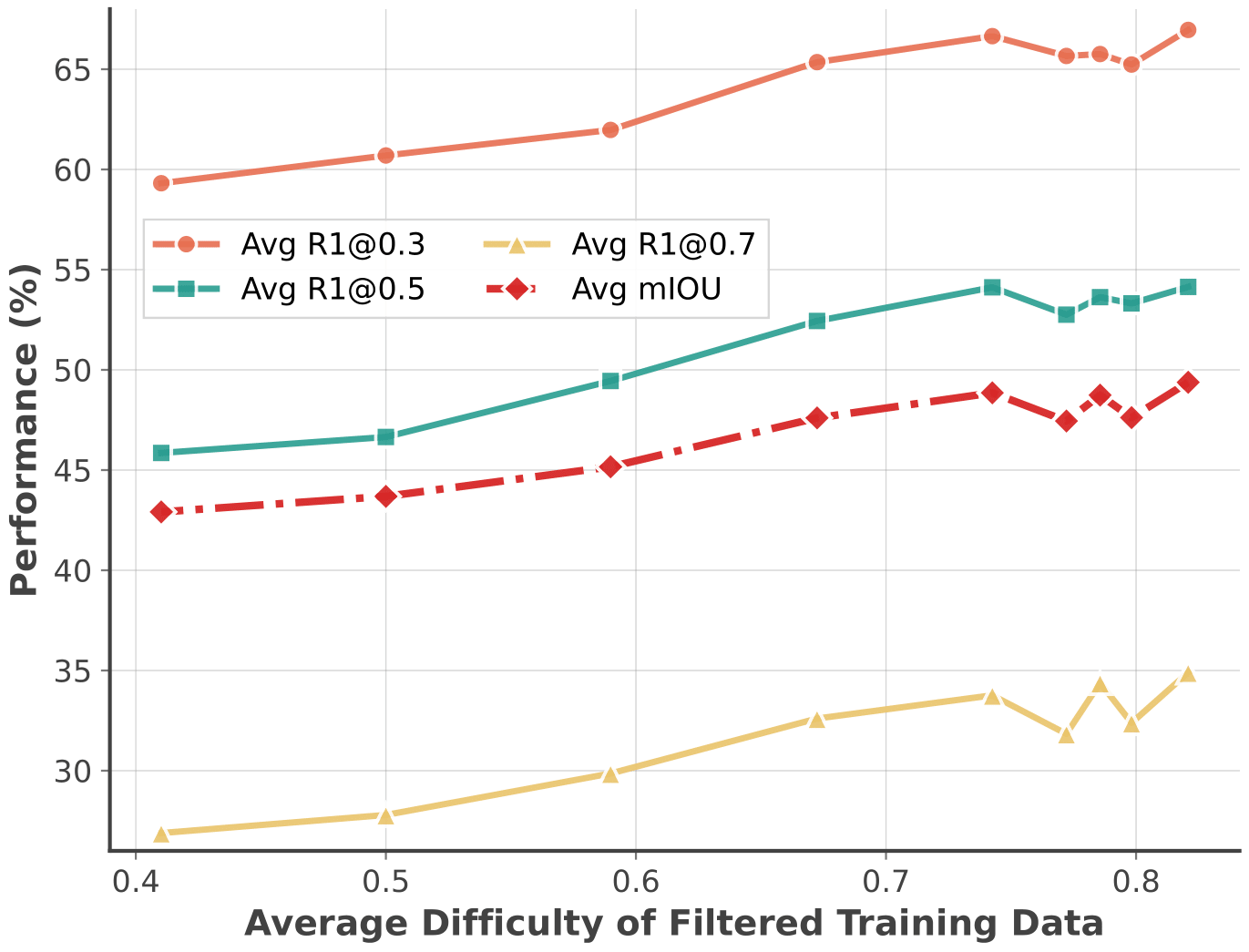
(ii) How to effectively sample training data?
- We estimate the difficulty of each training sample by running offline inference with the model to be trained and compute IoU metrics.
- We sample data from Gaussian distributions with varying means μ to obtain training sets of distinct difficulty levels.
- Model performance improves with higher average sample difficulty, plateauing at difficulty > 0.75.
- Key insight: Selecting training samples with sufficiently high difficulty is crucial for RLVR performance.
TimeLens-Bench Leaderboard
Instructions for viewing the leaderboard:
- Separated View vs. Combined View: The Separated View displays Open-Source and Proprietary models in separate tables. The Combined View shows all models together.
- Sort by Metrics: You can click on any metric column header to sort the models by that specific metric.
To submit your results to the leaderboard, please contact junzhang00@foxmail.com.
Proprietary Models
| # | Model | Charades-TimeLens | ActivityNet-TimeLens | QVHighlights-TimeLens | Avg. | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1@ 0.3 |
R1@ 0.5 |
R1@ 0.7 |
mIoU | R1@ 0.3 |
R1@ 0.5 |
R1@ 0.7 |
mIoU | R1@ 0.3 |
R1@ 0.5 |
R1@ 0.7 |
mIoU | |||
Open-Source Models
| # | Model | Charades-TimeLens | ActivityNet-TimeLens | QVHighlights-TimeLens | Avg. | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| R1@ 0.3 |
R1@ 0.5 |
R1@ 0.7 |
mIoU | R1@ 0.3 |
R1@ 0.5 |
R1@ 0.7 |
mIoU | R1@ 0.3 |
R1@ 0.5 |
R1@ 0.7 |
mIoU | |||
BibTeX
@article{zhang2025timelens,
title={TimeLens: Rethinking Video Temporal Grounding with Multimodal LLMs},
author={Zhang, Jun and Wang, Teng and Ge, Yuying and Ge, Yixiao and Li, Xinhao and Shan, Ying and Wang, Limin},
journal={arXiv preprint arXiv:2512.14698},
year={2025}
}